
Перед тем как проводить исследования на данных, нужно исследовать сами данные. Достаточно ли их для анализа, какие гипотезы и факторы влияют на результат, а какие — чистая рулетка? На эти вопросы отвечает исследование данных — Exploratory Data Analysis (EDA). Его rdl by red_mad_robot и проводил для «АгроТерры».
О клиенте
«АгроТерра» входит в топ-20 крупнейших владельцев сельскохозяйственной земли в России по версии BEFL и обрабатывает более 200 тыс. га. Компания занимается выращиваем, хранением и реализацией различных сельскохозяйственных культур и ежегодно производит около 1 млн тонн готовой продукции, семян сои, пшеницы, гибридов кукурузы и подсолнечника и оказывает услуги региональным агропроизводителям. Сейчас «АгроТерра» активно развивает углубленную аналитику, чтобы с её помощью повышать маржинальность и операционную эффективность бизнеса.
Пару слов про исследование данных
Часто исследование данных начинают с проверки гипотез бизнеса. Например, у агрокомпании есть такая гипотеза: если проводить химические обработки в определённый срок, урожайность повысится. Дальше эта гипотеза либо подтверждается, либо опровергается. Факторов может быть больше: не только сроки обработок, но и множество других. Тогда строятся модели многофакторного анализа, которые учитывают общие закономерности.
Исследование данных, или EDA — Exploratory Data Analysis, — отдельный процесс, нацеленный на исследование качества данных, где ключевое — поиск общих закономерностей, генерация новых гипотез и экспериментов.
Например, при анализе данных может выясниться, что на урожайность несколько факторов влияют сильнее остальных, но в каком порядке эти факторы идут — достоверно выяснить невозможно. То есть они важнее, но какой из них самый важный, из текущих данных непонятно.
Но достаточно ли у компании данных, чтобы предсказать повышение урожайности? Это тоже повод для исследования данных.
Повод для исследования
В разных отраслях доступны разные объёмы данных. Компании, чьими продуктами пользуются миллионы людей, собирают много данных — это действительно big data. У агробизнеса их гораздо меньше — он ограничен географией, а производственный цикл здесь длится целый год. Для проверки новых гипотез здесь на помощь приходят синтетические данные. Их основное отличие от обычных заключается в том, что они создаются алгоритмами, а не реальными событиями. Синтетические данные активно применяются для развития моделей машинного обучения.
В «АгроТерре» уже на протяжении нескольких лет успешно используют модель многофакторного анализа (МФА). С её помощью определяют факторы, повлиявшие на маржинальность. Например, засеяли 100 полей и собрали урожай. С одного поля урожайность — пять тонн на гектар, с другого — три. Возникает вопрос: «Что не так?». Именно на него и отвечает МФА. Но саму модель было сложно развивать, дорабатывать и обогащать синтетическими данными, потому что в её основе лежал закрытый код.
Тогда «АгроТерра» приняла решение развивать свои модели на open source, когда исходный код открыт для анализа и редактирования. Клиент обратился за нашей экспертизой, чтобы улучшить модель.
Мы привыкли к тому, что инструменты искусственного интеллекта используются в различных сферах, но едва ли многие думают, что модели машинного обучения можно успешно применять и в сельском хозяйстве. В «АгроТерре» мы уделяем большое внимание сбору данных и уже накопили их достаточно для того, чтобы на их основе можно было генерировать синтетические данные, позволяющие вывести точность наших аналитических моделей на новый уровень. Для исследования качества этих данных и поиска наиболее подходящих инструментов их анализа мы обратились к rdl by red_mad_robot.
Мы начали с исследования данных. Оно состояло из нескольких этапов:
этап по исследованию данных, когда команда rdl by red_mad_robot изучала результаты предыдущей модели многофакторного анализа и текущие наборы данных, варианты их обогащения;
этап по разработке альтернативных методов решения задачи, построению моделей, выбору наилучшей из них, построению рейтинга факторов и оценке экономической значимости.
Исследование данных
Так как исходный код модели был проприетарным, то есть закрытым, нам фактически нужно было воссоздать модель с нуля. А перед этим перебрать несколько реализаций и найти максимально близкий к исходному алгоритм.
Чтобы понять, какой из алгоритмов ведёт нас не туда, мы выбрали три метрики: точность, стабильность и ширину доверительного интервала.
Выбор метрик
Модель на основе множества чисел предсказывала, какой будет результат, — это задача регрессии. Для неё обычно используют метрику абсолютной или квадратичной ошибки.
Мы выбрали абсолютную ошибку, потому что она меньше реагирует на всякие аномальные выбросы в данных. Так как данных было мало, такие выбросы находились регулярно.
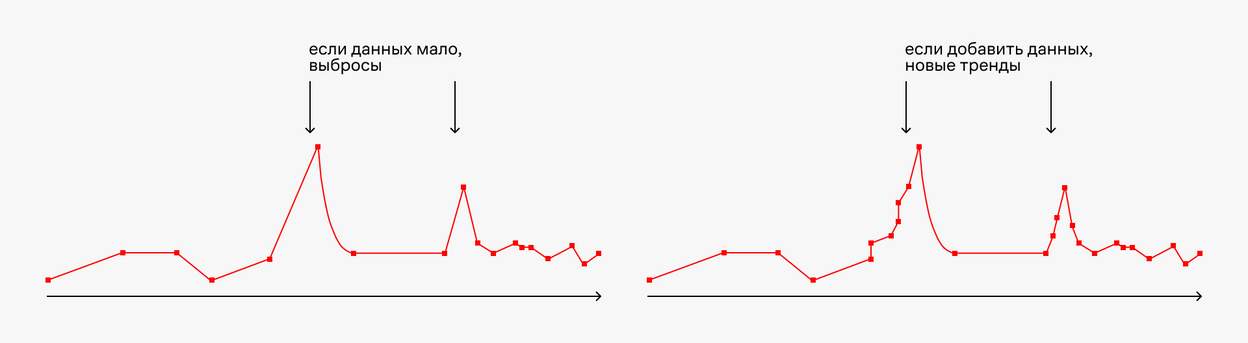
Абсолютную ошибку мы называли точностью. По сути, это была метрика здравого смысла. Она позволяла посмотреть, насколько точно модель предсказывает урожайность.
Если клиент засеет новое поле, действительно ли он сможет полагаться на закономерности, которые нашла модель? Или же модель ничего не выучила и просто подогнала ответы как по решебнику? Если на новых данных точность будет высокой, значит модель действительно что-то поняла. Но при этом данные не должны сильно отличаться от тех, на которых модель училась, иначе результаты будут непредсказуемыми.
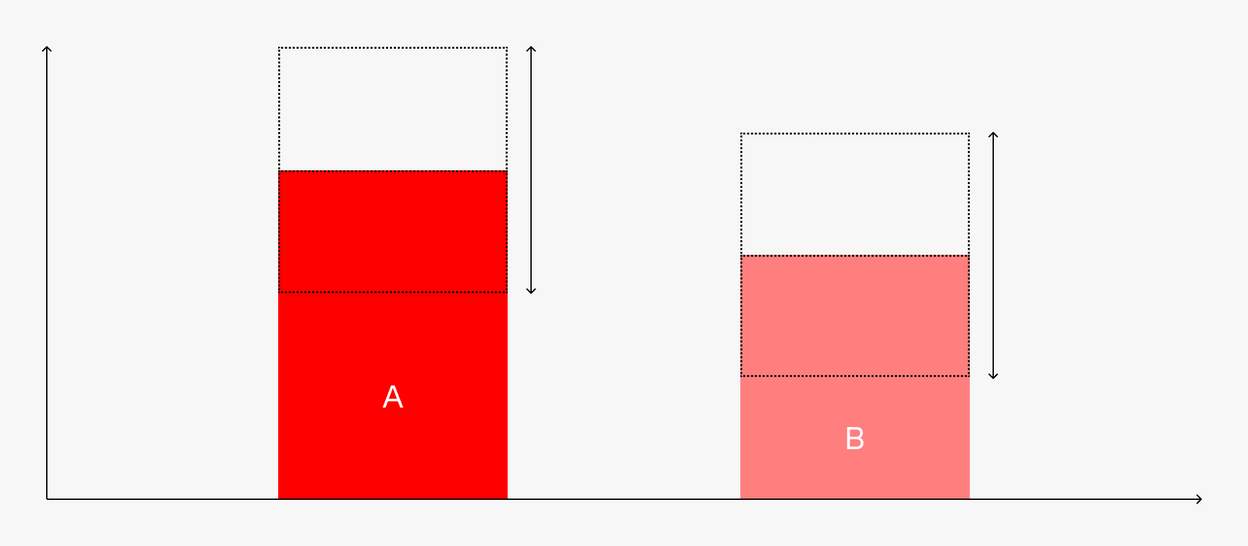
Ширина доверительного интервала — важная метрика для бизнес-задачи клиента, чтобы он мог понимать, какой фактор важнее другого. Например, первый фактор приводит к увеличению урожая на 0,4 т/га с разбросом ±0,35 т/га. Второй увеличивает урожайность на 0,35 т/га с разбросом 0.3 т/га. Это значит, что мы не можем предсказать, какой из факторов важнее при небольшом количестве наблюдений. Разброс нивелирует положение фактора в рейтинге.
Стабильность позволяла определить, насколько факторы меняют свой рейтинг относительно друг друга при запуске моделей с разными настройками и на разных выборках данных. На больших данных эта метрика не нужна, потому что нам не нужно запускать модель снова, результаты репрезентативны и детерминированы. Но при небольшом количестве записей нам приходилось учитывать стабильность предсказаний моделей.
Если данных недостаточно, модели при обучении становятся крайне неустойчивыми и при разных параметрах инициализации дают значительно разные результаты. Именно поэтому важно в таких задачах делать выбор в пользу моделей, меньше подверженных влиянию случайных данных, не связанных с решаемой задачей.
Выбор лучшей модели
В сравнении участвовало три модели машинного обучения: случайный лес, бустинг и стекинг. На инфографиках ниже видна разница между ними.

На самом деле моделей было больше, но это были вариации бустинга, поэтому рассказывать о них мы не будем.
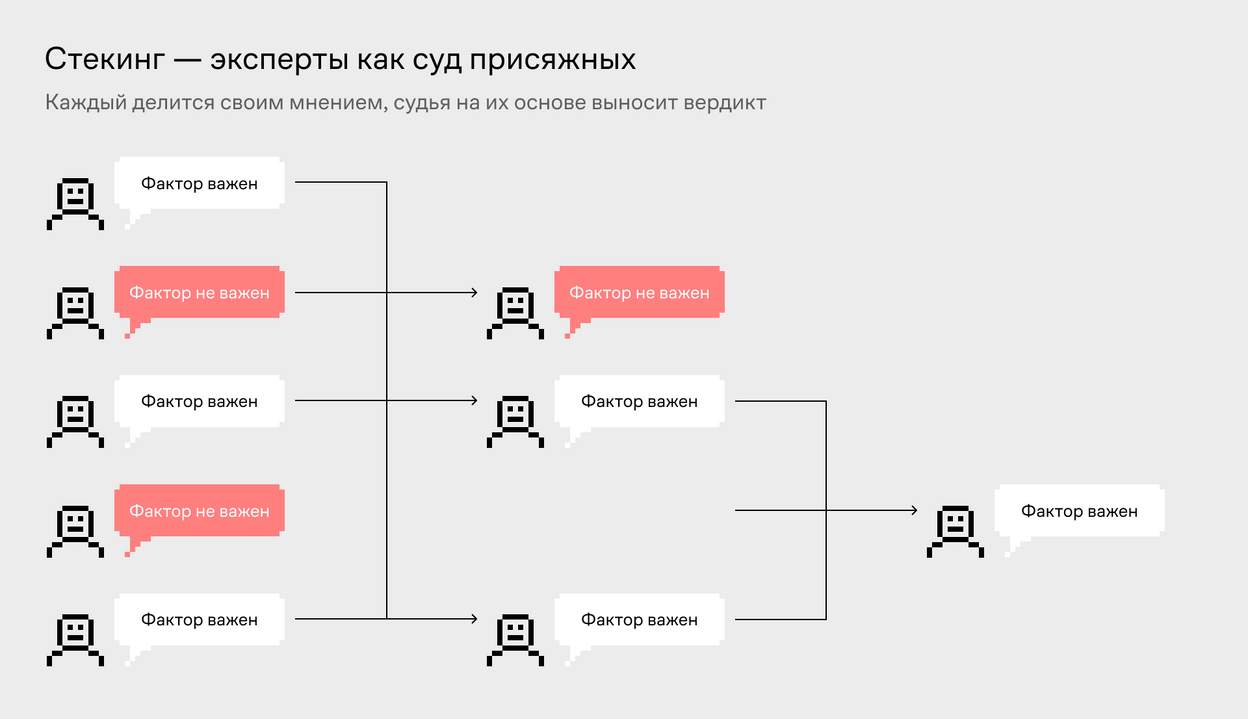
Лучше всего себя показали бустинг и стекинг. Между ними не было статистически значимой разницы, но стекинг был архитектурно лучше, поэтому мы выбрали его.
Модель стекинга — по факту собрание экспертов, где каждая модель предсказывает свой результат, а финальная модель линейной регрессии использует результаты их предсказаний и выносит вердикт.
Зачем нужна такая сложная архитектура? Данных было мало, поэтому одному классу моделей доверять не стоит. Несколько разных моделей могут лучше обобщить зависимости в данных.
Выжать максимум из лучшей модели
Итак, мы выбрали инструментарий для исследования данных — модель стекинга. По метрикам наша модель была максимально близка к исходной.
Но клиент хотел понять, какой максимум можно выжать из данных и модели. Пока модель уверенно предсказывала топ факторов, но не порядок факторов внутри топа, — этому мешал широкий доверительный интервал.
Чтобы улучшить модель, нам предоставили данные за два предыдущих года. В результате получился топ факторов, который сильно отличался от первого.
Этим данным нужно доверять с осторожностью. В них не было истории по полям, возможно, на каких-то полях выращивали другие культуры. Ну и история по полям — фактор сам по себе, который можно комбинировать с другими и искать на основе этого интересные закономерности.
Поделимся способами, которые также хорошо повлияли на метрики.
Сокращение количества факторов
В машинном обучении не все доступные характеристики полезны для решения задачи. Это явление называется проклятием размерности: в сложных системах с большим количеством факторов увеличивается количество «шума». Поэтому мы отбирали факторы так: обучали модель, а потом по каждому фактору брали и полностью перемешивали значения. А потом смотрели на качество предсказания. Если качество резко проседало, то мы брали фактор в финальный пул, а если нет, то фактор считали незначимым.
Это мы проделали в самом начале исследования, и это дало хороший прирост точности.
Генерация новых факторов
Мы пробовали создавать новые факторы с помощью нейросети, и это дало прирост в точности. Но проблема была в том, что они не были полезными для бизнеса. Мы от них отказались.
Тогда мы вместе с агрономами составили комбинации из факторов, которые кажутся им логичными. Например, разбивка осадков по месяцам. Генерация новых факторов даёт хороший прирост метрик. Это стало нашей первой рекомендацией клиенту по возможному улучшению модели.
Обогащение модели данными из открытых источников
Клиент предоставил нам открытые данные по температуре и осадкам. Из них можно было выделять дополнительные факторы — например, когда несколько дней подряд шёл дождь или была засуха. Логично, что это могло повлиять на урожайность. Факторы были понятны агрономам, поэтому мы добавили их в модель.
Открытые данные повысили точность модели на 20% относительно модели клиента. Разницу по остальным метрикам мы не смотрели, потому что измеряли их финально, когда открытые данные уже были в датасете.
Что делать, если данных недостаточно
Совет «собирайте данные» очевиден. Но с высокой вероятностью их всё равно бы не хватило, даже если бы клиент хранил эти данные с момента основания компании. Давайте разберёмся, что в таком случае можно сделать.
В коммерческих проектах нет единственно правильного способа что-то сделать с малым количеством данных. Если бы он существовал, мир был бы лучше. Есть несколько подходов: например, повторить несколько важных строчек и исказить их каким-то «шумом», нагенерировать данных с помощью той же нейросети, анализировать данные блоками (добавив временную составляющую). Иногда эти подходы могут принести результат, но если нет — остаётся только изменить постановку исходной задачи. Есть шанс, что её удастся решить, главное, чтобы она тоже имела бизнес-ценность.
На чём нужно сосредоточиться:
1_
На подключении температурных данных с привязкой по геолокации полей — по нашим результатам, это может дать до трети прироста в метриках.
2_
На спектроскопии почвы — мы делали анализ агротеха и решений машинного обучения, в нём практически все и используют эти данные. Они вряд ли есть в открытом доступе, но мы видели датасеты Европы, Латинской Америки и Индии. Из них можно взять характеристики почвы: ревитализация (восстановление плодородности), влажность, усталость.
3_
На отслеживании геолокации сборочной техники. На поля меньше 30 га может заезжать один грузовик и собирать урожай с нескольких полей. Также грузовик может собрать оставшийся на поле урожай и поехать загружать свободный объём на следующее поле. В этом случае мы не знаем точно, сколько собрано урожая с каждого поля, поэтому модель будет давать ошибку. Нужно точно знать, что 100 тонн с поля X — это действительно данные только по этому полю.
Результаты
Мы воспроизвели модель, приближенную к изначальной. Переписали её на Python и передали все исходники кода — теперь её можно запускать на собственной инфраструктуре клиента, изучать и улучшать. В процессе получилось проанализировать ещё несколько алгоритмов, кроме стекинга. Схожие результаты дал алгоритм случайного леса.
С текущим количеством данных получилось выделить три наиболее экономически значимых фактора, но точно сказать, какие из них важнее, нельзя.
Из интересных выводов: сокращение количества факторов влияет на точность. Отбирать факторы лучше перед исследованием, с привлечением агрономов.
Зачем вообще нужно инвестировать в исследование данных
Бизнесу очень важно понимать ограничения той или иной технологии, ведь часто машинное обучение и большие данные представляются как серебряные пули, решение всех проблем и ответ на невысказанные вопросы.
Если у вас есть бизнес-задача, для решения которой понадобятся данные, вы можете обратиться к нам за их исследованием. Мы поможем понять, достаточно ли их для анализа и какой максимум из них можно выжать.
Даже если для решения этой задачи данных окажется недостаточно, это не значит, что для другой бизнес-задачи их тоже не хватит. По сравнению с полноценным развёртыванием модели исследование данных не требует капитальных затрат на инфраструктуру и серверы, не говоря уже о цене ошибки при принятии решений на недостаточных данных.
***
Кстати, у нас открыта вакансия Data Scientist (Computer Vision).
Над материалом работали:
текст — Стас Звягинцев,
редактура — Виталик Балашов,
иллюстрации — Юля Ефимова.
Чтобы ничего не пропустить, следи за развитием цифры вместе с нами:
Да пребудет с тобой сила роботов! 🤖