
За 15 лет работы red_mad_robot база знаний компании сильно масштабировалась. Появление новых артефактов и рост количества проектов усложнили актуализацию знаний для сотрудников. Времени на обновление данных часто не хватает, поиск материалов стал сложнее, а часть информации вообще канула в лету вместе с ушедшими сотрудниками. В итоге пересылка документов в чатах и многочисленные гугл-таблички стали самым простым, но не самым удобным и тем более безопасным вариантом.
Но мы ведь роботы, и там, где белковые пересылают документы в чатах, мы создаём умные сервисы. Так родилась база знаний Smarty.
Что такое Smarty
Бизнес-юнит NDT, выросший из пет-проекта разработчиков, взял на себя задачу создания Smarty — умной базы знаний red_mad_robot. На основе RAG-архитектуры команда разработала систему, использующую облачные и локальные большие языковые модели для генерации ответов и поддержки диалогов. Мы регулярно тестировали интерфейс и дорабатывали дизайн, а вскоре после запуска дополнили веб-версию телеграм-ботом, который стал полноценным участником рабочих чатов. Сначала точность ответов не превышала 40%. Точность мы измеряем на основе составленных Q& А вопросов для нашего датасета. Мы постоянно проходимся по датасету и данным методом RAGAS и дополняем секцию Q& А тестовыми вопросами для анализа данных. Что такое RAG и RAGAS мы расскажем ниже в тексте. В итоге у нас получилось поднять точность ответов до 95%, значительно сократив время поиска информации и уменьшив нагрузку на службу поддержки. Это довольно высокий показатель среди аналогичных продуктов на рынке.
Мы спроектировали Smarty на основе on-premise-модели — это самый безопасный вариант. Чтобы добиться наилучшего результата, мы ускоряли LLM, автоматизировали, уменьшали размеры, выбирали лучшие. Помимо языковой модели, Smarty использует ещё три:
модель векторизации данных (переводит текст в цифры),
модель реранжирования результатов (упорядочивает по месту найденные семантические кусочки для обогащения информации),
классификатор Guardrails (запрещает LLM общаться на темы, несуществующие в датасете и запрещённые законом).
RAG — поисковик на стероидах
В red_mad_robot все знания, начиная от того, как уйти в отпуск, заканчивая оборудованием дочерних компаний, хранились в Confluence. Если в его поиске задать вопрос «Как уйти в отпуск?», результатом будет 1082 страницы разной степени неактуальности. Это приводит пользователя в ужас. Так работает индексируемый поиск по полному вхождению слова, в том числе и поисковики вроде Google.
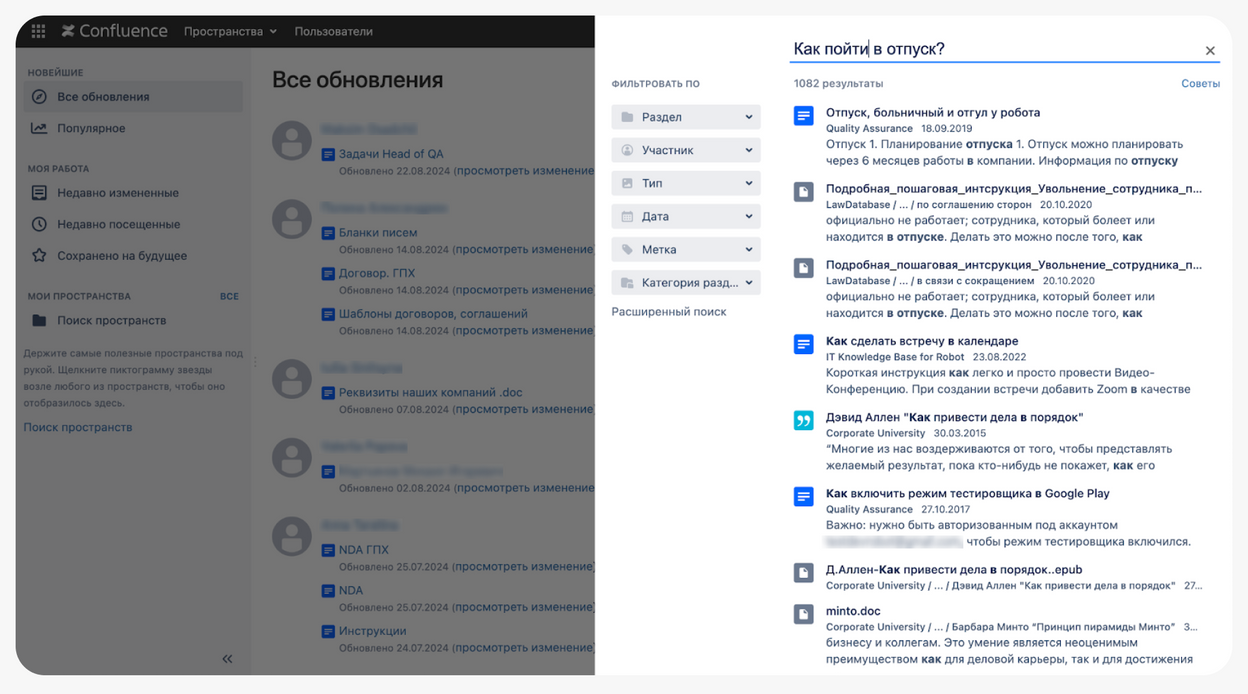
База знаний на основе RAG позволяет получить чёткий сформулированный ответ на свой вопрос со ссылками на источники. Но как это работает?
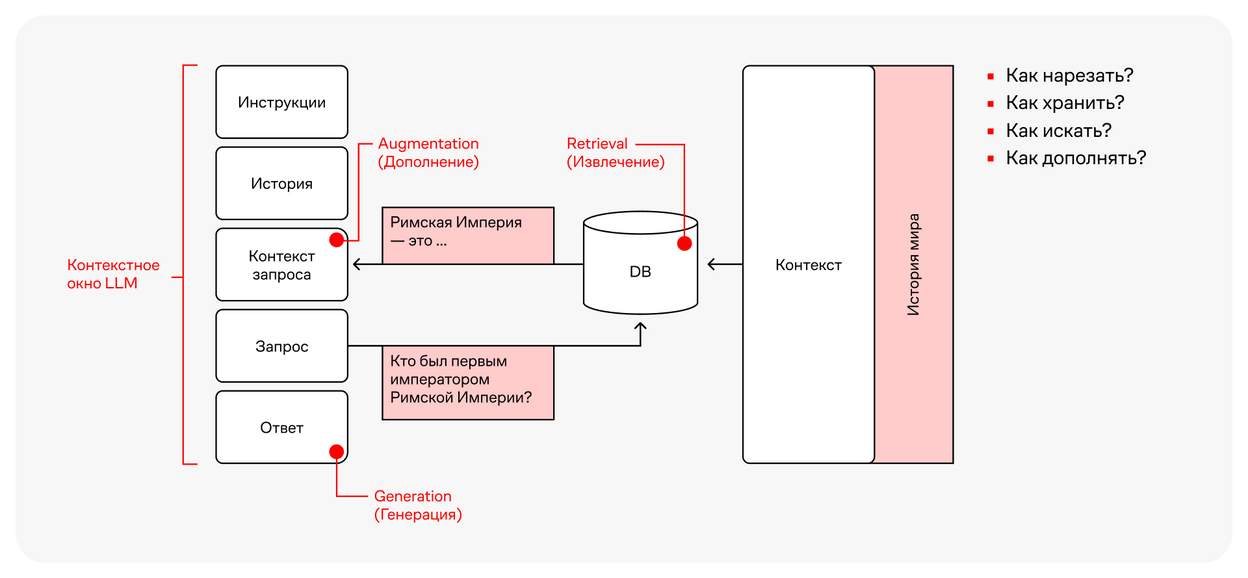
Обычный индексируемый поиск разбирает запрос пользователя на отдельные слова и ищет максимально релевантные вхождения среди своих данных, предлагая ссылки на источники в качестве ответа. В поиске, основанном на RAG, всё работает так:
Запрос пользователя попадает в семантический механизм поиска, который ищет «близость» со всеми документами или знаниями, которые есть в базе.
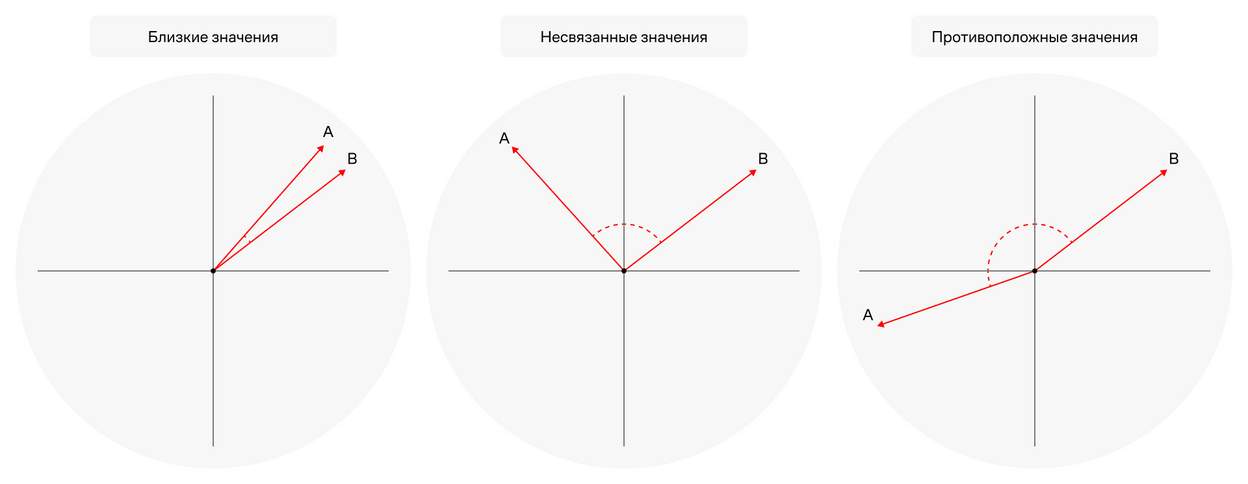
Документы, вместо полного вхождения в слова, имеют вектор — набор чисел в векторном пространстве. Запрос при этом тоже превращается в вектор.
Специальный механизм поиска ищет максимально релевантные по вектору ответы. То есть буквально сравнивает углы между векторами в пространстве. Если угол маленький, значит знания семантически похожи. Чем меньше значение вектора, тем ближе по смыслу информация к запросу пользователя.
Мы получаем куски текста из разных документов, которые по смыслу подходят к запросу, и «отдаём» их в LLM с заранее заготовленным промптом, который выглядит примерно так:
LLM генерирует конечный ответ для пользователя и даёт ссылку на все источники.
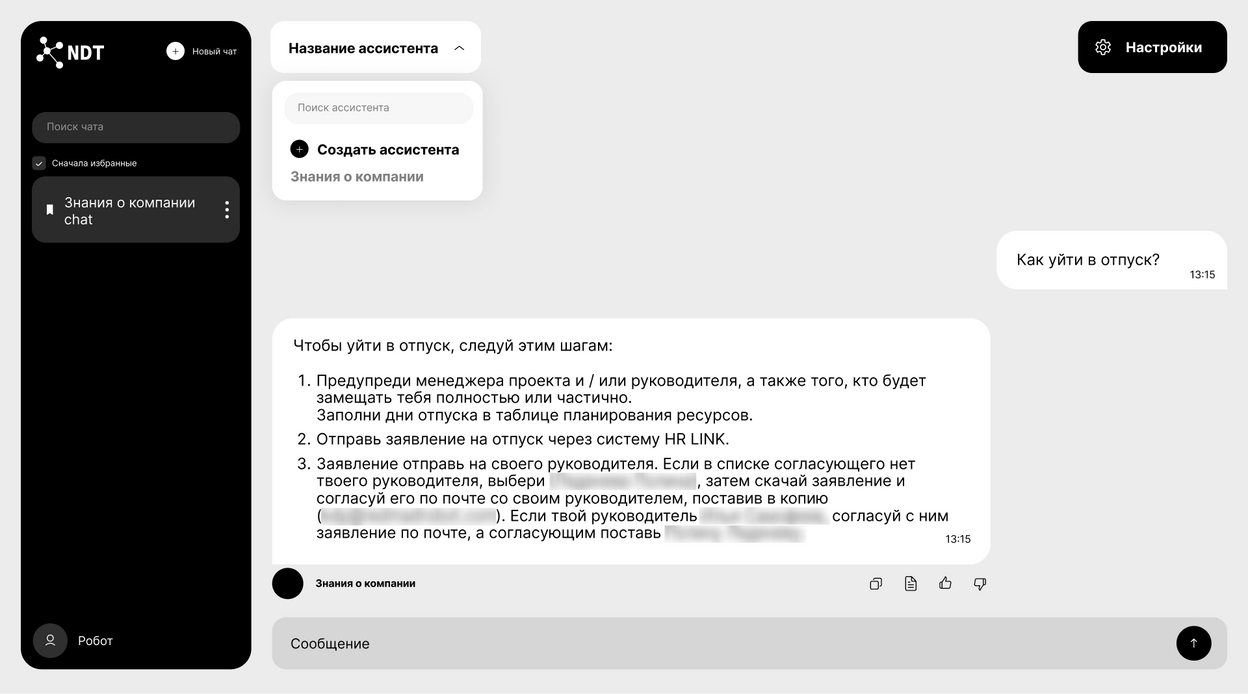
Кожаные больше не нужны?
Smarty — это мультиагентная сеть, которая самостоятельно создаёт базу знаний, тестирует её и валидирует без участия человека. Есть даже агент, который смотрит на результаты остальных агентов и даёт им рекомендации о том, как увеличить точность.
Мы написали и настроили агентов самостоятельно, создав цепочку с минимальным участием человека:
Документ попадает в систему авторазметки. Затем система кладёт документ в векторную базу данных и сама создаёт себе вопросы. После этого отправляет ответы человеку на валидацию. Если человека устраивает результат, он даёт команду запустить тест, система его запускает и даёт рекомендации. Затем человек смотрит, что ещё нужно исправить. Система исправляет, запускает новый тест, и в итоге мы получаем нужные метрики.
Это самообучающаяся система, которая может превратить один текстовый документ в домен знаний. Агент-авторазметчик позволяет разбить огромное полотно текста на логические блоки, не теряя смысла и не переписывая слова, по такой схеме:
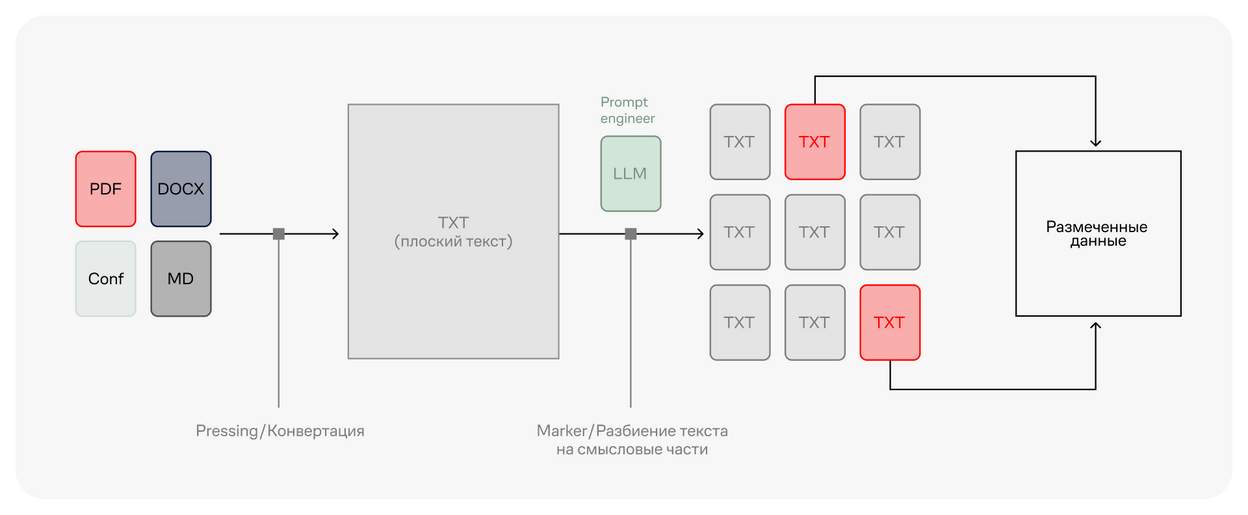
А дальше весь размеченный текст преобразуется в векторы с помощью модели эмбеддинга и хранится в векторной базе данных. При использовании продвинутого RAG-поиска, на котором мы и построили Smarty, система выбирает более 30 релевантных запросу кусков текста из векторной базы данных, реранжирует их и отправляет в LLM топ-5 подходящих от этих 30. Затем LLM формулирует ответ, который проходит ещё один цикл проверки Guardrails и RAGAS (автотестирования качества).
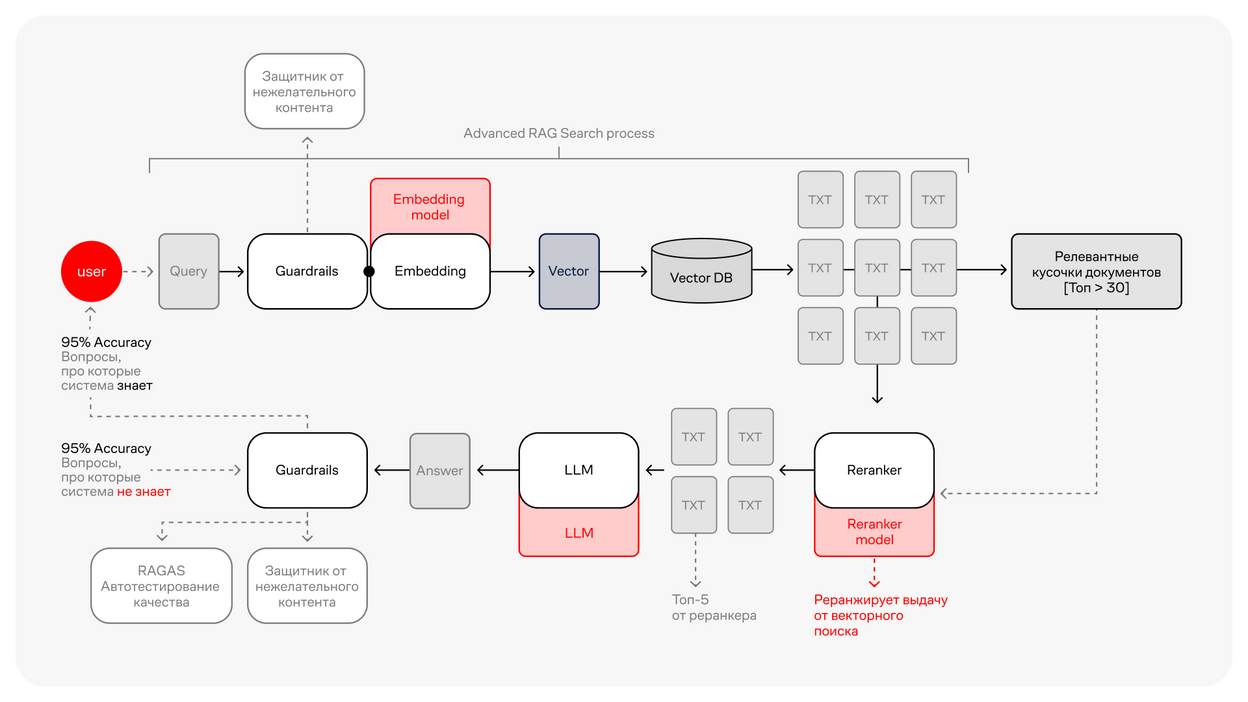
Таким образом достигается точность ответов выше 95% не только на вопрос, контекст которых система уже знает, но и на вопрос, контекст которого системе вообще не знаком.
Но ведь можно просто взять и обучить собственную LLM
Конечно! Если у вас есть лишний $1млн, огромное количество токенов и вычислительных мощностей, то можно. Но даже при этом — не факт, что сработает. Система на основе RAG позволяет в разы дешевле и эффективнее настроить работу LLM, чтобы она решала задачи компании.
Мы кастомизируем агентов для разметки, тестирования и создания датасета и промпт для LLM, чтобы модель сохраняла tone of voice компании. Мы зашили в RAG-модель основы ToV и редакционной политики red_mad_robot, и теперь Smarty отвечает так же, как это сделал бы любой другой сотрудник компании — дружелюбно, лаконично и с уместным юмором.
Все модели, с которыми мы работаем, подняты на нашем железе, автомасштабируются, кластеризируются. В общем, из разных кубиков этого RAG-конструктора мы собрали Smarty для себя и теперь создаём индивидуальные решения и для наших клиентов.
Что нам дала Smarty
95% правильных ответов.
Значительно сократилось время на поиск информации.
Уменьшилась нагрузка на техподдержку.
Ассистент научился давать краткие и расширенные ответы.
Он умеет задавать наводящие вопросы и давать ссылки на материалы.
Создали гибкую систему, работающую как on-cloud, так и on-premise.
Планы на будущее
Кроме того, чтобы захватить мир, дальше мы планируем:
1_
Создать поиск по неявным знаниям, которые «сидят» на сотрудниках — научить умную базу знаний давать советы, к кому обратиться по тому или иному вопросу. Вшить в базу глубокие знания по процессам и компетенциям. А ещё мы прорабатываем возможность вытаскивать такие знания через аудиосообщения — это минимальные трудозатраты для сотрудников, всё остальное сделают агенты.
2_
Создать систему, которая сама «достаёт» нужные знания из людей, чтобы она определяла, чего ей не хватает и спрашивала у сотрудников.
3_
Тестировать на Smarty разработки в области создания ИИ-агентов, чтобы в перспективе умная база знаний стала полноценным напарником в работе.
***
Над материалом работали:
текст — Алина Ладыгина,
иллюстрации — Петя Галицкий.