
Два AI-агента для разных задач
ФСК внедрили GenAI в работу с контрагентами и управление знаниями, чтобы оптимизировать внутренние процессы. Теперь AI-агент собирает данные обо всех жилых комплексах в единую базу, помогая менеджерам и поддержке быстрее отвечать на вопросы клиентов и подрядчиков.
Одна из главных задач — предотвратить ошибки (галлюцинации), которые могли бы привести к репутационным и финансовым рискам. Например, клиент спрашивает: «Есть ли в этой квартире панорамные окна?», а AI-агент отвечает неправильно, что влияет на решение о покупке. Чтобы избежать таких ситуаций, мы внедрили смарт-платформу с двумя workflow AI-агентами:
1_
Для контрагентов: помогает с ответами на часто задаваемые вопросы, разгружая службу технической поддержки.
2_
Для сотрудников: оптимизирует поиск по внутренним документам, облегчая доступ сотрудников к корпоративной базе знаний.
Ожидаемый эффект: снижение нагрузки на команду поддержки и коммерческий департамент на 30–40%.
Наши агенты не просто выполняют предопределенные инструкции, а динамически принимают решения на основе контекста запроса. Router-компонент системы анализирует входящие вопросы и самостоятельно определяет к каким доменам знаний следует обратиться для формирования полного ответа. Мы используем подход CoT + SO для определения и классификации нужного домена знаний.
Как AI-агент обрабатывает данные
ФСК передали нам документацию для обучения модели: PDF-файлы с инструкциями и FAQ. Чтобы AI-агент мог точно отвечать на вопросы, нужно было правильно структурировать данные.
Первый этап — извлечение данных. Если данные загружены хаотично, а их структура не проверена, часть информации может потеряться. Поэтому AI-агент сначала анализирует тип и структуру документов и выбирает оптимальный метод обработки данных. Для простых текстовых данных без проблемных кодировок используются стандартные фреймворки, но при работе с таблицами или сложноструктурированными документами агент автоматически привлекает OCR-технологии или vision-language модели, например, qwen2.5-VL-7B-Instruct. Так можно извлекать данные из самых разных источников, включая сканы и изображения.
Далее используется чанкинг — разбиение текста на смысловые фрагменты. В этом проекте мы применили несколько методов разбиения: paragraph chunker, semantic chunker и sliding window. Такой подход позволил сохранить контекст и повысить точность ответов. Агент сам выбирает подход на основе классификации данных, у нас есть свои секреты — какой подход лучше для разных типов данных.
AI-агент разметки на старте применял фиксированный алгоритм чанкинга. В последних итерациях для sliding window мы классифицировали данные так, чтобы агент мог сам выбрать размер окна, перекрытие или объединение для оптимального сохранения контекста. При обнаружении сложных взаимосвязей агент может инициировать дополнительные циклы обработки.
RAG — ключевой подход в смарт-платформе
Retrieval-Augmented Generation (RAG) позволяет AI-модели не просто генерировать ответы, а извлекать релевантные данные из базы перед выдачей результата. Это значительно повышает точность системы.
Retrieval-Augmented Generation (RAG) позволяет AI-модели не просто генерировать ответы, а извлекать релевантные данные из базы перед выдачей результата. Это решает проблемы дорогостоящего дообучения модели в ситуациях, когда данных недостаточно или это экономически нецелесообразно. Вместо этого мы помещаем найденные данные непосредственно в контекст запроса, используя подход In-Context Learning, что позволяет модели работать с актуальной информацией без необходимости постоянного переобучения.
В отличие от обычных RAG-систем внутри нашей часть агентов способна к рефлексии — подсмотрели в решениях deep research и даже делали их сравнение. Они оценивают достаточность извлеченной информации и при необходимости могут запустить дополнительные циклы поиска, используя переформулированные запросы или обращаясь к альтернативным доменам знаний.
Как это работает:
1_
Retrieval — поиск и извлечение информации.
2_
Augmented — дополнение запроса пользователя найденными данными.
3_
Generation — генерация ответа с учётом полученной информации.
Document Management Service
Сервис управления документами — ключевой компонент смарт-платформы. AI-агенты обрабатывают документы разных форматов (PDF, DOCX, PPTX, Excel), распознают структуру, выделяют ключевые сущности (имена, даты, события) и превращают их в markdown или HTML, далее нарезают и векторизируют, что упрощает поиск и анализ данных.
Далее система:
Индексирует документы, чтобы ускорить поиск и хранение.
Автоматически классифицирует информацию для удобного доступа.
Использует SO (structured output), что позволяет получать не просто текстовые ответы, а данные в заданном формате.
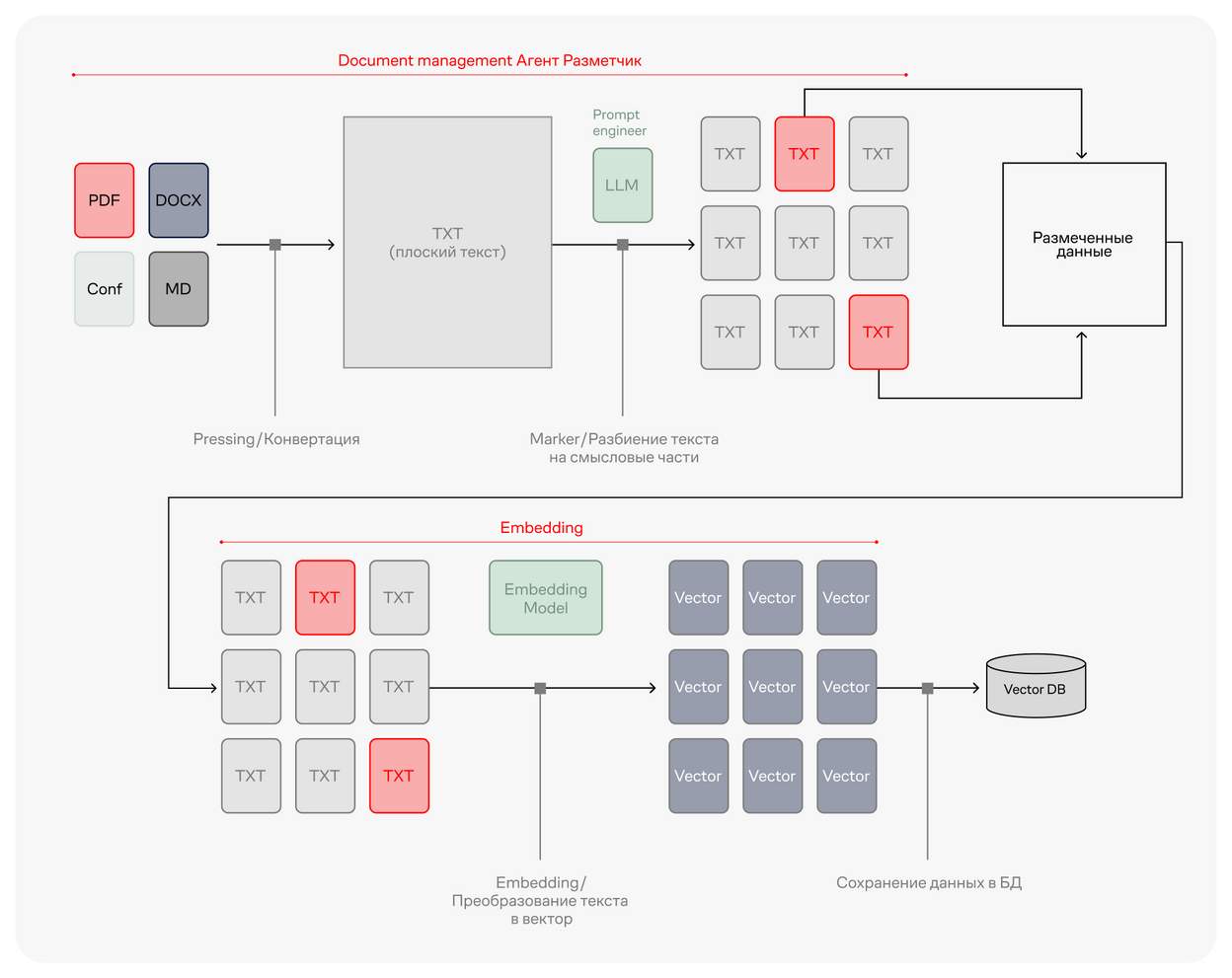
Структурированный вывод SO (structured output) позволяет не только получать ответ от системы, но и задавать его формат, что упрощает разметку данных. AI-агент автоматически анализирует тысячи документов и преобразует их в нужную структуру за несколько часов, исключая необходимость ручной обработки.
Как автоматизировать парсинг данных
Первый этап — извлечение данных. Если данные загружены хаотично, а их структура не проверена, часть информации может потеряться. Поэтому AI-агент сначала анализирует документы и выделяет важные элементы. Фактически мы делаем классификации — тут нам помогает всё тот же qwen2.5-VL-7B-Instruct, а также vision-language модель, которая может воспринимать информацию визуально.
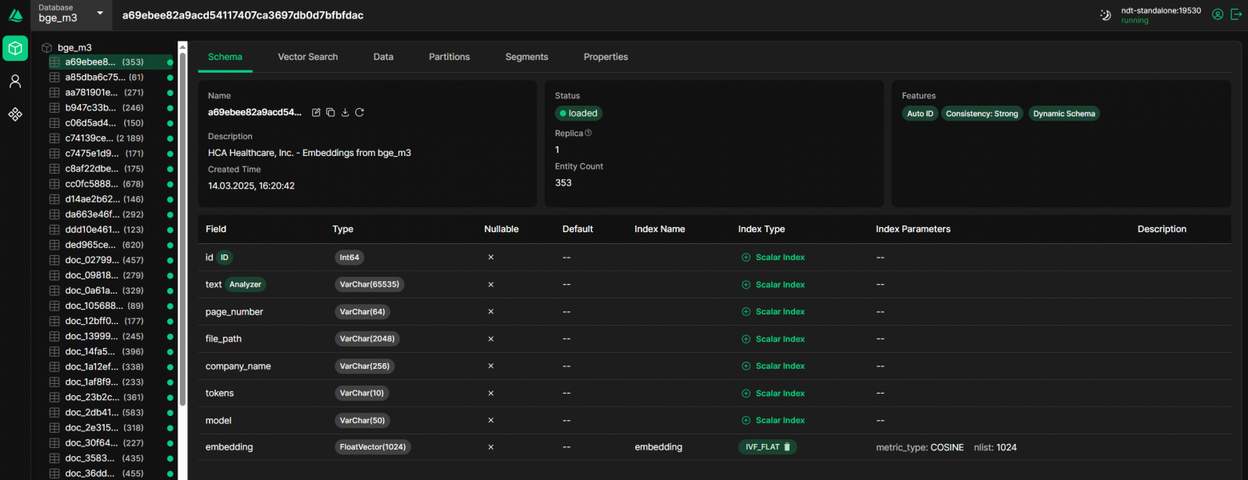
Далее при извлечении данных из документов мы индексируем каждую страницу и помещаем полный текст во внутреннее хранилище системы. Таким образом мы получаем следующую структуру в базе данных:
id
text
page number
file path
tokens
model
embedding
После извлечения данные преобразуются в векторные представления, мы используем сразу несколько моделей: bge-m3 и multilingual-e5-large. Точность поиска внутри RAG во многом зависит от выбора модели векторизации. Для финансовых документов лучше подходит bge-m3, для классических систем HR или Q& A с разметкой query и passage — multilingual-e5-large.
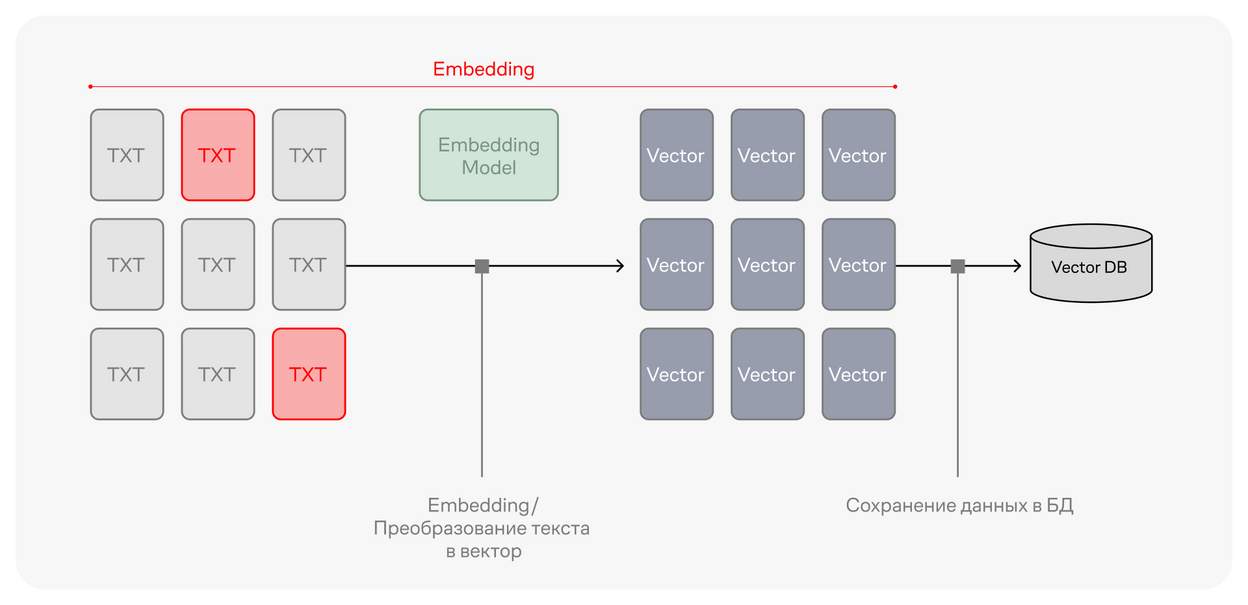
Сначала текстовые данные преобразуются в эмбеддинги — векторные представления, используемые для анализа, размер каждого вектора 1024d. Затем они помещаются в векторное хранилище, мы используем в продуктовой среде Milvus.
За основной пайплайн отвечает модель qwen2.5-VL-7B-Instruct от t-tech/T-lite-it-1.0. Кстати, а за весь инференс у нас отвечает vLLM фреймворк. Для вычитки контекста и финального ответа мы взяли модель побольше — qwen2.5-VL-32B-Instruct от t-tech/T-pro-it-1.0. Для лучшего результата мы используем модели только в точности FP16
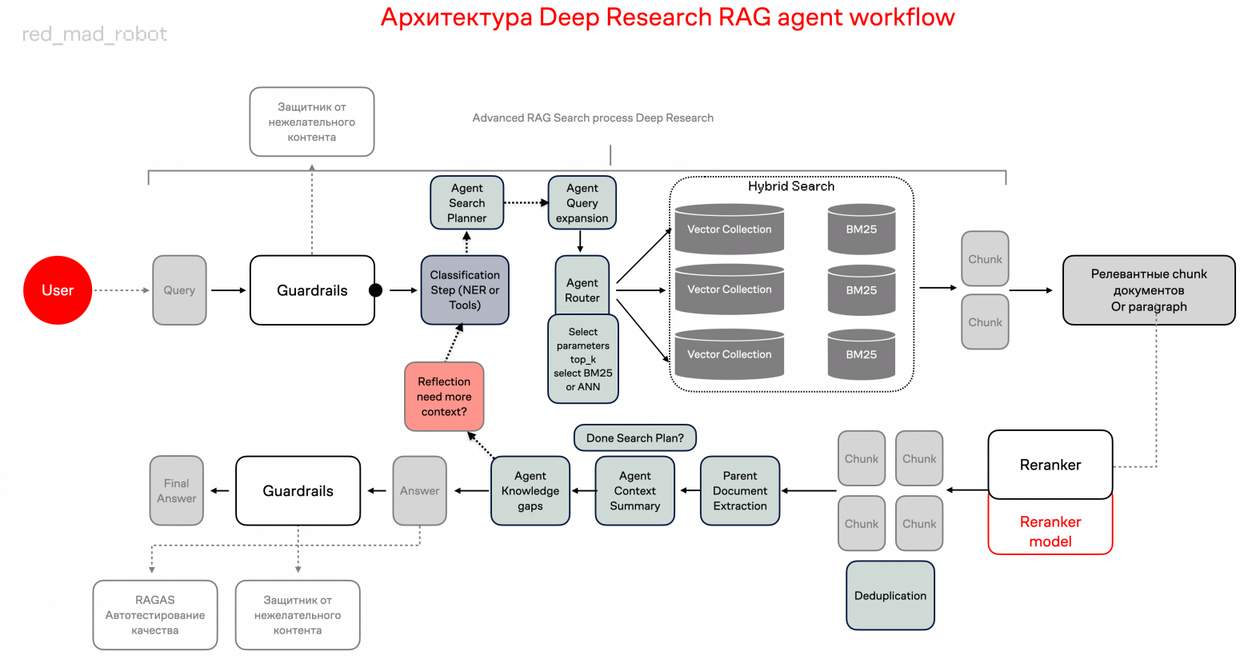
Как работает процесс поиска информации
1_
Мы получаем запрос пользователя, агент классификатор анализирует его, извлекает именные сущности и тип запроса, например, vector search или FTS.
2_
Следующий агент получает эти данные и запрос пользователя, анализирует их с помощью CoT и SO и выбирает домен знаний в котором их нужно искать — возвращает нам JSON с domain_id и search_params, например, top_k.
3_
Ещё один агент анализирует полученные данные от предыдущих агентов и выбирает тип поиска: FTS или Basic ANN Search.
4_
После получения ответа от поисковой системы мы извлекаем полный текст найденных страниц по подходу parent document extraction. Агент объединяет данные и выдаёт ответ на базе CoT и SO — возвращает reasoning_steps, relevant document, response и sources. Для структурированного вывода без ошибок форматирования JSON лучше всего подходит xgrammar.
Сейчас у нас в разработке продвинутый пайплайн, в который будет добавлена рефлексия на основе анализа пробелов в знаниях.
Как это устроено:
А как же тестирование?
Фреймворк RAGAS — это библиотека, которая предоставляет инструменты для оценки приложений, созданных на базе LLM. Мы адаптировали библиотеку под свои нужды — взяли необходимые метрики и применили подход LLM as a judge, который помогает оценивать точность RAG и повышать качество ответов. Вместо ручной проверки, занимающей недели, система за минуты автоматически анализирует ошибки и предлагает корректировки.
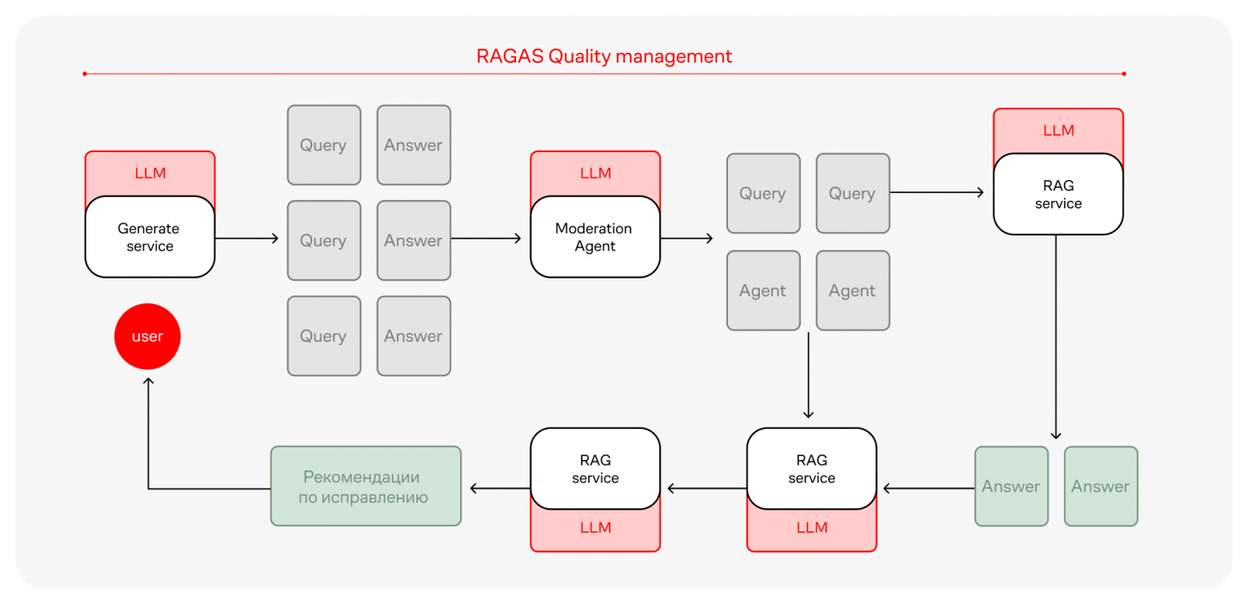
Процесс выглядит так:
1_
Система тестирует RAG и выявляет слабые места.
2_
На основе ошибок формируются рекомендации для доработки модели.
3_
После исправлений проводится повторное тестирование, пока точность не достигнет необходимого уровня.
Так нам удалось сократить время на обработку данных и генерацию контента, которое мы потратили на улучшение датасета. Благодаря LLM as a judge мы быстро можем корректировать ответы системы и выдавать лучший результат с каждой итерацией.
В работе с данными самое ценное — время. Наша платформа показывает, как AI-агенты могут за часы выполнять задачи, на которые раньше уходили недели. Встроенная система тестирования RAGAS гарантирует качество результатов. Мы автоматизировали не отдельные операции, а целые процессы работы с корпоративными знаниями
Итоги
Всего за два месяца мы разработали и внедрили систему workflow AI-агентов более чем на 1 млн токенов знаний. В результате:
Нагрузка на поддержку и коммерческий департамент снизилась на 30–40% за счёт автоматизации обработки запросов.
Клиенты получают более релевантные ответы, что повышает уровень сервиса и удовлетворённости пользователей.
Этот кейс показывает, что AI-агенты, построенные по заданному workflow, могут добегать до результата быстрее чем классические RPA-системы. И это не просто технологический тренд, а реальный инструмент повышения скорости внедрения GenAI в бизнес.
Использованный нами подход к построению агентной системы соответствует современной концепции workflow агентов, описанной Anthropic, где сочетаются элементы определённой структуры и динамического принятия решений. В дальнейшем мы планируем развивать систему в сторону большей автономности.
***
Над материалом работали:
текст — Валера Ковальский, Алексей Жданов, Никита Белов
редактура — Игорь Решетников
иллюстрации — Петя Галицкий